Enterprise Cloud Operations and Governance
A case study on cloud security.
Many customers start by creating separate cloud (google, aws, azure etc)
accounts for each environment (dev, pre-prod, prod etc) for each
application. This helps create a strong separation between all resources in
each account. However, this approach can create great operational
challenges.
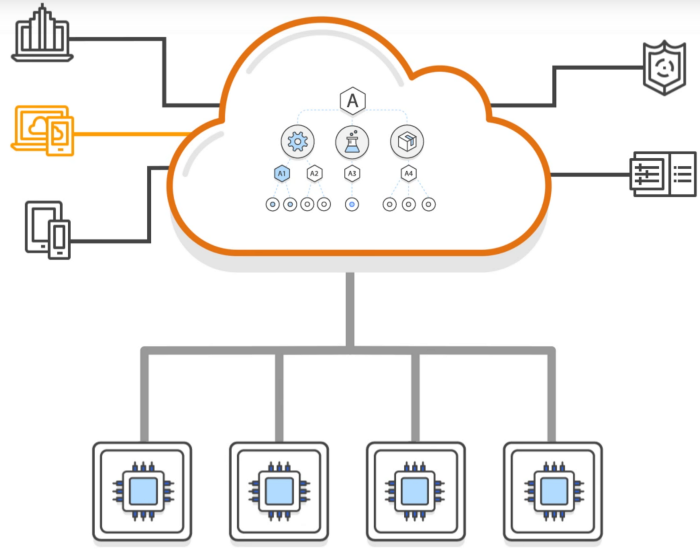
Let’s imagine an enterprise organisation with 1000+ service teams that are
hosted on cloud. A centrally managed organisation with a bunch of tools and
automation processes helps cloud ops to centrally manage billing, control
access, compliance, security and share resources across many AWS accounts.
This blog is going to throw some light on how cloud Ops teams manage all of
those thousands of cloud accounts and 100s of resources in each accounts
using two simple use cases. Also we will understand, why it is very
important for organisation and for their customers. In the end, I will share
one learning from a devops standpoint and share a few links to some of the
best practices.
The “Capital One” Use case:
Capital One Data theft of 106M customers: A misconfigured cloud
resource (WAF) caused the cloud security failure
WAF (web application firewall) is a type of cloud security service to access
one’s VPC (virtual private cloud) resources.
If any EC2 (elastic cloud compute, a unix/windows box in the cloud) is open
to accept incoming traffic from 0.0.0.0/* IP range then it allows internet
traffic to the EC2. Generally, WAF rules can be configured prevent 0.0.0.0/*
to reach to any resource in the VPC. At a lower level at least a security
group can be added to filter incoming traffic. The suspect twitted about the
brag.
The hacker twitted after she took a dump of all customer data using their S3
and aurora DB.
Once inside, she launched an EC2 instance to trick the AWS Metadata Service
into trusting it, thereby receiving credentials to access and decrypt data
stored in an S3 bucket.
This incident created paranoia across industry and suddenly bringing in lots
of focus to these cloud services settings and configurations.
How to prevent this from happening?
Security and Compliance is a shared responsibility between cloud infra
providers (aws) and the customer (consumer company). It is commonly referred
to as Security “of” the Cloud versus Security “in” the Cloud.
Example from AWS cloud: for centralised governance, billing, security
policies etc. through aws organization.
A master account service that gives a centralised control to all of resources
that is owned by a company.
Security, compliance and governance Policies:
Do you see those emails from your cloud operations team?
With a message like “Policy Violated — Action needed”
Cloud security team notifies regularly about any misconfiguration
This is a security framework published by the Center for Internet Security as
the foundation of your security policy library, to expedite your
time-to-value and achieve consistent configurations across your cloud
footprint.
AWS Organization
A lot of things goes on continuously behind the scene.
Fundamental unit of an accounts is called Organisational Unit(OU) OUs allow the
ability to arbitrarily group accounts and other OUs together so that they
can be administered as a single unit. A Service Control Policy (SCP) is
applied to an OU. These policies can describe the access and resource
restrictions for the OU. A root is a top-level parent node in the hierarchy
of an organisation that can contain organisational units (OUs) and accounts.
A root contains every AWS account in the organisation.
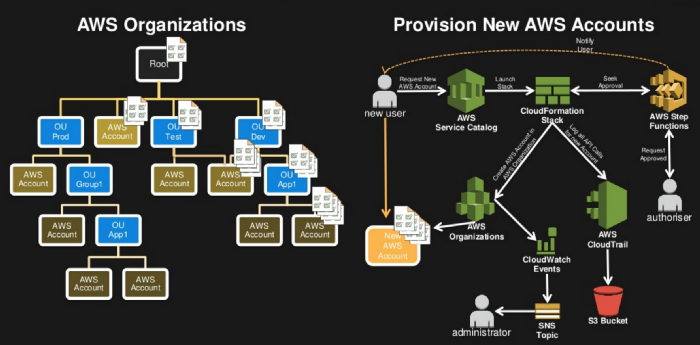
OUs accounts and managed by a root in an aws organization
Product: Assets which form part of the Product or support the Product
in some way. The things you want to build.
Core: These assets are perhaps less obvious, but are just as
important. They are the supporting cast to your Product.
Use of automation to avoid mistakes
A governing cloud can be created using CLI
create-gov-cloud-account
--email
--account-name
[--role-name ]
[--iam-user-access-to-billing ]
[--cli-input-json ]
[--generate-cli-skeleton ]
Create a security policy -
aws organizations create-policy --content ~/org/policies/waf-policy.json --name AllowAllS3Actions, --type SERVICE_CONTROL_POLICY --description "Allows delegation of all S3 actions"
A hypothetical “Production incident” use case:
The incident:
Customers were unable to view their attached images from a public CDN URLs in
their attached documents.
It was a controlled traffic therefore the blast radius was very small and
spread was slow. Those customers were not able to view their uploaded logos
on invoices, and other financial documents as well. Documents such as
Invoices are viewed from many different places such as emails, customer’s
viewing portal, within also within the main product, HTMLs/PDF etc. For some
reason customers logos from cdn go missing in all of those places where they
could have viewed an Invoice and other customer docs.
We did not have pager or alerts on cdn urls. The care team got to know this
first when annoyed customers started sending messages over VOC/emails. By
the time we fix the problem it was 10+ hours. Not a happy situation at all.
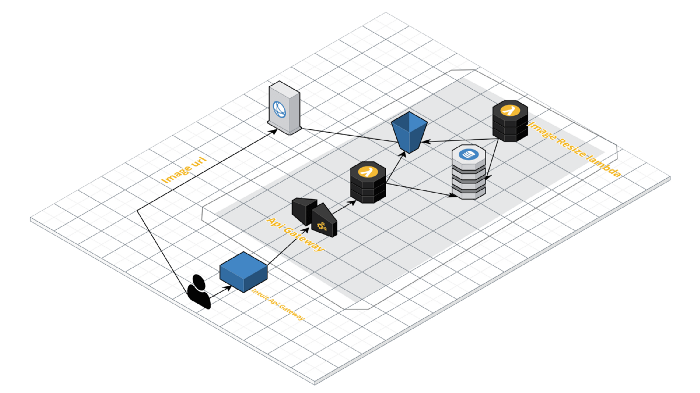
The document image processing is a micro service and it is on a
server-less architecture.
Historically, the micro service was using a single AWS account for
development, pre-production and production environments separated via aws
tagging. One main reason is being AWS cost optimisation the org wanted to
manage lesser accounts. But that’s not the issue. Another caveat, the AWS
account was created with a pre-production tagged on it. That implied to —
the logo service was running on pre-production account, from the cloud
operations perspective.
The service creates a reference to a CDN URLs for viewing the logos in the
emails/invoices/other places. On that fine day morning a new security policy
(WAF rule) was created and applied to block any traffic from outside office
intranet for all pre-production accounts including all resources based on
the account tag.
Best practices
By now you may have co-related both use cases and understood both cases were
because of not following best practices. Automation to enforce and automatic
detection and remediation is the key to reduce the vulnerability window.
Regular communication of changes, alerts on production traffics helps
minimise friction and failed customer experiences and outages. Every day a
new set of security vulnerabilities are uncovered, making development teams
aware of those and their remediation helps such outages and preventing any
kind of breaching into private networks. All resources in a cloud account
needs to tagged properly with an organisational standard policy. Resources
Those belongs to prod and development needs to be tagged so that root is
aware of what WAF to be applied.
A right organisational tagging
strategy makes a difference how we govern our accounts and
resources in it. In the beginning, we may start with multiple environments
from one account such as production database and production database, if the
organisation tagging policy is designed right for those requirements and
notifying for the same to teams makes a great deal.
Reference:
I found a bunch of materials among them AWS documentation
on account management is one of the best ones. There is a
course
on governance and compliance — seems good.
One best practice blog of separating development
and production accounts.
Not in AWS? no issues, each of those big players have laid out their best
practices. Here’s Google
Cloud account management.
@ranadeep_bhuyan